2D-3D KONVERSION
Auf dieser Seite stelle ich aktuelle Pakete zur 2D-3D-Konversion zum Download bereit.
Gemeinsame Eigenschaft aller dieser KI-Pakete ist ihre Portabilität, d.h. sie funktionieren
komplett unabhängig von einer Internetanbindung. Dafür sind die Hardware-Anforderungen
entsprechend hoch, es werden leistungsfähige CPUs und GPUs benötigt.
Die KI-Entwicklung zur Herstellung von Tiefenmasken ist hochdynamisch, deshalb ist diese Seite
immer nur bedingt aktuell. Auch stelle ich nicht alle Pakete, die ich bisher zusammengestellt habe,
zur Verfügung. Momentan gibt es hier drei Pakete, DepthStick V5.2, DepthStick V5.5 und DepthStick V6.0.
- DepthStick V5.2: Implementiert DepthAnythingV2 und Video-DepthAnything.
DepthAnythingV2 ist eines der führenden Modelle zu Konvertierung von Bildern (besonders das Modell Large).
Auch für Comics, Animationen und Gemälden (Mona Lisa) anwendbar.
Video-DepthAnything wird empfohlen zur Konvertierung von Videos, verarbeitet mehrere Frames auf einmal. - DepthStick V5.5: Implementiert DepthPro.
DepthPro wurde ausschließlich mit photorealistischen Bildern trainiert, insbesondere mit Porträts
und wurde zusätzlich auf extreme Kantenschärfe optimiert. Interessante Alternative zu DepthAnythingV2.
- DepthStick V6.0: Implementiert DepthAnythingV3.
Modell Giant mit gewissen Detailverbesserungen gegenüber DepthAnythingV2. Experimantal: Tiefenmasken aus Stereobildern.
DepthStick V5.2
DepthStick V5.2 vereint die Pakete Depth-Anything-V2 (https://github.com/DepthAnything/Depth-Anything-V2)
zur Erzeugung von Tiefenmaskenbildern und Video-Depth-Anything (https://github.com/DepthAnything/Video-Depth-Anything)
zur Erzeugung von konsistenen Tiefenmaskenvideos.
Für Depth-Anything-V2 kann man die Modelle Small, Base, Large und Giant auswählen,
für Video-Depth-Anything gibt es nur die Modelle Small, Base und Large. Die großen Modelle
rechnen detaillierter, aber dafür auch deutlich langsamer als die kleinen Modelle.
Die großen Modelle werden bei der erstmaligen Verwendung heruntergeladen, die kleinen Modell werden im Archiv ausgeliefert.
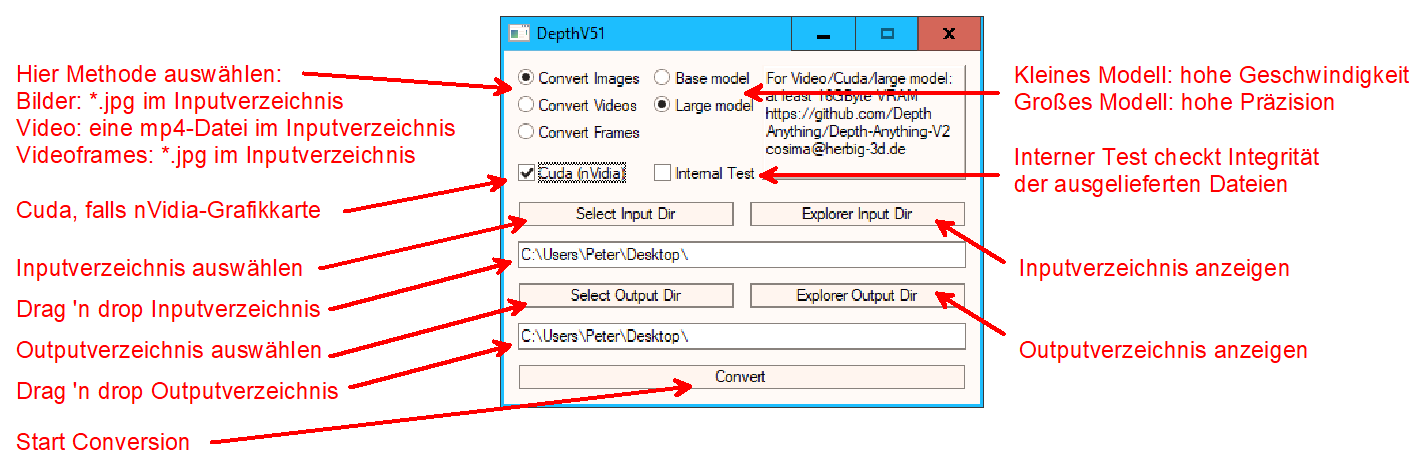
Die Oberfläche von DepthV52
- Convert Images: Für alle *.jpg-Bilder im ausgwählten Verzeichnis werden Tiefenmasken-Bilder erzeugt.
- Convert Video: Für alle *.mp4-Videos im ausgwählten Verzeichnis werden Tiefenmasken-Videos erzeugt.
- Convert Frames: Für alle *.jpg-Videoframes im ausgwählten Verzeichnis werden Tiefenmasken-Frames erzeugt.
Die jpg-Dateien werden als Frames eines Videos angesehen. Die Ergebnisse sind identisch wie bei "Convert Video",
sind aber nicht in einem Videocontainer enthalten sondern werden als Einzelframes abgespeichert.
- Bei Convert Video und Convert Frames sind die erzeugen Tiefenmasken frei von Sprüngen und Flimmern.
- Mit Small model, Base model, Large model oder Giant model wählen Sie ein KI-Modell. Die großen Modell haben
mehr Details, rechnen dafür aber auch deutlich langsamer, siehe Tabelle unten.
- Mit Cuda aktiviert man die GPU der nVidia-Grafikkarten. Die Konvertierung von Videos macht nur mit Verwendung
von Cuda Sinn (ohne Cuda entstehen selbst bei kürzesten Videos stundenlange Rechenzeiten).
Cuda ermöglicht kürzere Rechenzeiten und höhere Auflösungen (ohne Cuda constant 518 Pixel). - Bei aktiviertem Button Max Size wird die interne Auflösung an den vorhandenen VRAM angepasst.
Ohne Max Size beträgt die interne Auflösung constant 518 Pixel. - Der Interne Test verwendet zur Konversion ein mitgeliefertes Bild bzw. ein mitgeliefertes Video. Die Buttons zur Wahl
eines Input- und Output-Verzeichnisses sind ausgegraut. Man kann aber Explorerfenster der beiden Verzeichnisse öffnen.
- Bei aktivierter Pause hält das Script nach Beendigung der Konversion an. Dies dient zu lesen von Fehlermeldungen.
Mit Select Input Dir und Select Output Dir werden die Verzeichnisse für Input und Output gewählt.
- Explorer Input Dir und Explorer Output Dir dienen zur Anzeige und zur Kontrolle der Verzeichnisse.
- Tipp: Mit Input Dir = "<path>\l" (das originale Monobild) und Output Dir = "<path>\r" (die berechnete Tiefenmaske)
kann im nächsten Schritt sofort Cosima gestartet werden (InputMode = 9) ohne weitere Verschiebe- oder Kopieraktionen .
Hardware-Voraussetzungen:
Bilder lassen sich mit einer modernen CPU auch ohne Cuda konvertieren, Videos nicht.
Für Video: Das Small model benötigt mindestens 6GByte VRAM, Base und Large mindestens 16GByte.
Alles oberhalb einer RTX 1060 sollte prinzipiell funktionieren, wer eine neue Grafikkarte kaufen möchte,
nicht unterhalb einer RTX 5060-16GByte (Achtung, die Modelle werden mit verschiedenen VRAM-Ausbaustufen angeboten.)
Cuda (Compute Unified Device Architecture) ist ein Markenzeichen von nVidia.
Download:
 Download KI Software DepthStick V5.2 (5.3) GByte:
DepthStick_V52
Download KI Software DepthStick V5.2 (5.3) GByte:
DepthStick_V52
Troubleshooting:
- Datei- und Ordnernamen dürfen keine Umlaute oder andere Sonderzeichen enthalten.
- Zur Konversion werden nur *.jpg-Bilder bzw. *.mp4-Videos akzeptiert.
- Nur in einem Verzeichnis mit Schreibrechten entpacken, also z.B. nicht in C:\Programme!
- Maximale Länge für die Videokonversion: etwa 1800 full-HD Frames (vielleicht mehr bei mehr RAM/VRAM).
- Empfehlung, falls das Entzippen nicht auf Anhieb klappen sollte: 7-zip.de
- Hinweise zum Download: Sowohl die DepthStick-Archive als auch die KI-Modelle sind sehr grosse Dateien.
Falls es beim Download zu wiederholten Abbrüchen kommen sollte, wird die Verwendung eines Downloadmanagers,
z.B der Free Download Manager , empfohlen.
Link zum Archiv DepthStick_V52.zip https://www.dropbox.com/scl/fi/e1jdj5wdpfgly19emvvqr/DepthStick_V52.zip?rlkey=g9fmiddgyjsgswtsc2k59opxz&dl=1
Link zum Large model: https://huggingface.co/depth-anything/Depth-Anything-V2-Large/resolve/main/depth_anything_v2_vitl.pth
Large model kopieren nach: ~\DepthStick_V52\DepthAnythingV2\checkpoints\depth_anything_v2_vitl.pth
Link zum Giant model: https://huggingface.co/likeabruh/depth_anything_v2_vitg/resolve/main/depth_anything_v2_vitg.pth
Giant model kopieren nach: ~\DepthStick_V52\DepthAnythingV2\checkpoints\depth_anything_v2_vitg.pth
Link zum Video-Large model: https://huggingface.co/depth-anything/Video-Depth-Anything-Large/resolve/main/video_depth_anything_vitl.pth
Video-Large model kopieren nach: "~\DepthStick_V52\Video-Depth-AnythingV2\checkpoints\video_depth_anything_vitl.pth"
Performance:
- Die interne Auflösung der Tiefenmasken ist dynamisch abhängig von der Modellwahl und dem vorhandenen VRAM:
- Small model: startet bei 1 GByte VRAM mit max 700 Pixel bis 16 GByte mit max. 1450 Pixel Auflösung.
- Base model: startet bei 1 GByte VRAM mit max 550 Pixel bis 16 GByte mit max. 1250 Pixel Auflösung.
- Large model: Startet bei 2 GByte VRAM mit max 500 Pixel bis 16 GByte mit max. 1100 Pixel Auflösung.
- Giant model: Startet bei 6 GByte VRAM mit max 500 Pixel bis 16 GByte mit max. 950 Pixel Auflösung.
- ohne Cuda konstant 518 Pixel
- Bei Aktivierung von CUDA auf Systemen ohne CUDA gibt es einen Rückfall auf CPU.
- Bei Aktivierung von CUDA auf Systemen mit zuwenig VRAM gibt es einen Rückfall auf das kleinere Modell oder auf CPU.
Beispiel für einen i7-14700K/RTX 4060Ti (16GB VRAM)-Rechner:
Images/Video Model Time/CPU Time/GPU ===================================================== Images MonaLisa Base 1.4s 0.14s Images MonaLisa Large 5s 0.4s Images MonaLisa Giant xs xs Video Rollercoaster Base 2h 4m 52s 8s Video Rollercoaster Large - 4m 9s
DepthStick V5.5
DepthStick V5.5 arbeitet mit der KI DepthPro. Es werden ausschließlich Einzelbilder unterstützt, keine Videos.DepthPro bringt nur ein Modell mit (etwa wie Large), deswegen gibt es auch keine Modellauswahl.
Die interne Auflösung ist auf 1539 Pixel fixiert, eine dynamische Anpassung der Auflösung an das vorhandene VRAM entfällt somit.
Achtung: DepthPro ist nur für echte Fotos geeignet, keine Kunst, keine Comics (siehe Beispiele Rhododendron vs. Mona Lisa)!
Hardware-Voraussetzungen:
Die Verwendung von CUDA ist voreingestellt und läßt sich nicht abwählen, da mit CPU unzumutbar lange Rechenzeiten entstehen.
Download:
Download KI Software DepthStick V5.5 (2.7 GByte):
DepthStick_V55
Zur Bedienung:
DepthPro erzeugt defaultmäßig eine Tiefenmaske mit einer inversen Tiefenschätzung. Das vergößert den Detailreichtum im Vordergrund,
allerdings auf Kosten der Hintergrundstrukturen. Diese Eigenschaft mag für Porträts vorteilhaft sein, ist aber nicht für alle Bilder gleichmäßig geeignet.
Deshalb kann man in DepthStick_V55 auswählen, ob man die normale oder die inverse Tiefenschätzung bevorzugt.
Wählt man auto, werden zunächst beide Versionen erzeugt, aber nur die detaillreichere Maske abgespeichert.
Troubleshooting:
- Datei- und Ordnernamen dürfen keine Umlaute oder andere Sonderzeichen enthalten.
- Zur Konversion werden nur *.jpg-Bilder akzeptiert.
- Nur in einem Verzeichnis mit Schreibrechten entpacken, also z.B. nicht in C:\Programme!
- Empfehlung, falls das Entzippen nicht auf Anhieb klappen sollte: 7-zip.de
- Hinweise zum Download: Sowohl die DepthStick-Archive als auch die KI-Modelle sind sehr grosse Dateien.
Falls es beim Download zu wiederholten Abbrüchen kommen sollte, wird die Verwendung eines Downloadmanagers,
z.B der Free Download Manager , empfohlen.
Link zum Archiv DepthStick_V55.zip: https://www.dropbox.com/scl/fi/p8d080lsmml4xma0o3voo/DepthStick_V55.zip?rlkey=lnv9l2zxit8i63i59srkhe1t7&dl=1
Link zum Model: https://ml-site.cdn-apple.com/models/depth-pro/depth_pro.pt
Model kopieren nach: ~\DepthStick_V55\ml-depth-pro\checkpoints\depth-pro/depth_pro.pt
Performance:
--- kommt noch ---
DepthStick V6.0
DepthStick V5.x arbeitet mit der Version DepthAnythingV2. Inzwischen gibt es eine neue Version DepthAnythingV3.Auch dafür stelle ich mit DepthStick V6.0 ein Paket bereit, das im Prinzip genauso funktioniert wie die 5er-Serie,
allerdings mit folgenden Änderungen:
- Das Giant-Modell ist ein offizielles Release und kein "Hack" wie bei DepthStick V5.2.
- Die Implementierung für Videos arbeitet nur Frame-für-Frame, die Tiefenmaskenvideos sind nicht konsistent!
- Die Funktion 3D-Images -> Depth generiert zwei Tiefenmasken, eine linke im Verzeichnis "dl" und eine rechte im Verzeichnis "dr".
- Als Input für "3D-Images -> Depth" wird ein linkes Bild im Ordner "cl" und ein rechtes Bild im Ordner "cr" benötigt
(natürlich müssen die Bilder vorher cosimiert sein). - Die Funktion "3D-Images -> Depth" ist (leider) keine echte 3D->Tiefenmasken-Implementierung!
Hardware-Voraussetzungen:
Bilder lassen sich mit einer modernen CPU auch ohne Cuda konvertieren, Videos nicht.
Für Video: Das Small model benötigt mindestens 6GByte VRAM, Base und Large mindestens 16GByte.
Alles oberhalb einer RTX 1060 sollte prinzipiell funktionieren, wer eine neue Grafikkarte kaufen möchte,
nicht unterhalb einer RTX 5060-16GByte (Achtung, die Modelle werden mit verschiedenen VRAM-Ausbaustufen angeboten.)
Cuda (Compute Unified Device Architecture) ist ein Markenzeichen von nVidia.
Download:
Download KI Software DepthStick V6.0 (4.1 GByte):
DepthStick_V60
Troubleshooting:
- Datei- und Ordnernamen dürfen keine Umlaute oder andere Sonderzeichen enthalten.
- Zur Konversion werden nur *.jpg-Bilder bzw. *.mp4-Videos akzeptiert.
- Nur in einem Verzeichnis mit Schreibrechten entpacken, also z.B. nicht in C:\Programme!
- Empfehlung, falls das Entzippen nicht auf Anhieb klappen sollte: 7-zip.de
- Hinweise zum Download: Sowohl die DepthStick-Archive als auch die KI-Modelle sind sehr grosse Dateien.
Falls es beim Download zu wiederholten Abbrüchen kommen sollte, wird die Verwendung eines Downloadmanagers,
z.B der Free Download Manager , empfohlen.
Link zum Archiv DepthStick_V60.zip https://www.dropbox.com/scl/fi/xmpbxsym6vhkektjd6xsl/DepthStick_V60.zip?rlkey=e3kirzrctev9tzz8gcanvqbli&dl=1
Link zum Large model: https://huggingface.co/depth-anything/DA3-LARGE-1.1/resolve/main/model.safetensors
Large model kopieren nach: ~\DepthStick_V60\DepthAnythingV3\models\DA3-LARGE-1.1\model.safetensors"
Link zum Giant model: https://huggingface.co/depth-anything/DA3-GIANT-1.1/resolve/main/model.safetensors
Giant model kopieren nach: "~\DepthStick_V60\DepthAnythingV3\models\DA3-GIANT-1.1\model.safetensors"
Performance:
- Die interne Auflösung der Tiefenmasken ist dynamisch abhängig von der Modellwahl und dem vorhandenen VRAM:
- Base model: Startet bei 1 GByte VRAM mit max 700 Pixel bis max. 1920 Pixel Auflösung ab 3 GByte
- Large model: Startet bei 2 GByte VRAM mit max 500 Pixel bis max. 1920 Pixel Auflösung ab 6 GByte
- Giant model: Startet bei 6 GByte VRAM mit max 500 Pixel bis max. 1920 Pixel Auflösung ab 12 GByte
- ohne Cuda konstant 504 Pixel
- Bei Bildern ist CUDA etwa um den Faktor 10 schneller, bei Videos um den Faktor 1000!
- Bei Aktivierung von CUDA auf Systemen ohne CUDA gibt es einen Rückfall auf CPU.
- Bei Aktivierung von CUDA auf Systemen mit zuwenig VRAM gibt es einen Rückfall auf das kleinere Modell oder auf CPU.
Beispiel für einen i7-14700K/RTX 4060Ti (16GB VRAM)-Rechner:
Images/Video Model Time/CPU Time/GPU ===================================================== Images (1920x1028) Base 23.8s 0.45s Images (1920x1028) Large 84.5s 1.25s Images (1920x1028) Giant 314s 3.0s Video robot_unitree Base - 96.6s Video robot_unitree Large - 235.6s Video robot_unitree Giant - 648.9s
Kommentar
- Für Videos ist nach wie vor VideoDepthAnything (also DepthStick V5.2) das Mittel der erstenWahl!
- Für Bilder wird nach wie vor DepthAnythingV2 (also DepthStick V5.2, Modell Large) empfohlen für zuverlässige, konsistente Ergebnisse.
Bei Bildern mit vielen echten Hintergrunddetails lohnt sich vielleicht der Upgrade nach DepthAnythingV3 (DepthStick V6.0, Modell Giant),
allerdings neigt DepthAnythingV3 bei strukturlosen Hintergründen zu wolkigen Artefakten.
- Die Funktion 3D-Images -> Depth ist nur für Experimente und (noch) nicht für den produktiven Einsatze gedacht.
Es wird kein echter stereoskopischer Input verarbeitet! - DepthPro (DepthStick V5.5) hat seine Stärken bei fotorealistischen Bildern, vor allem Porträts. Ausprobieren lohnt sich in jedem Fall!
© Gerhard P. Herbig, 2026, back to cosima homepage